libfuzzer
llvm、clang-3.5 是不行的,fuzz编译选项无法使用
多参考下 google libfuzzer 学会写测试代码,其中还有大量的测试字典 fuzzers/dict
libfuzzer build:
灵活:通过实现接口的方式使用,可以对任意函数进行fuzzing
高效:在同一进程中进行fuzzing,无需大量fork()进程
便捷:提供了API接口,便于定制化和集成
但是没有dirty mode,需要编译时插桩
1 | apt-get install -y make autoconf automake libtool pkg-config zlib1g-dev |
usage
libFuzzer.a需要被静态链接到测试程序,并且会调用入口函数
fuzzer会跟踪哪些代码区域已经测试过,然后在输入数据的语料库上进行变异,来使代码覆盖率最大化。代码覆盖率的信息由 LLVM 的SanitizerCoverage 插桩提供。
1 | int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) |
1 | 编译一个cpp |
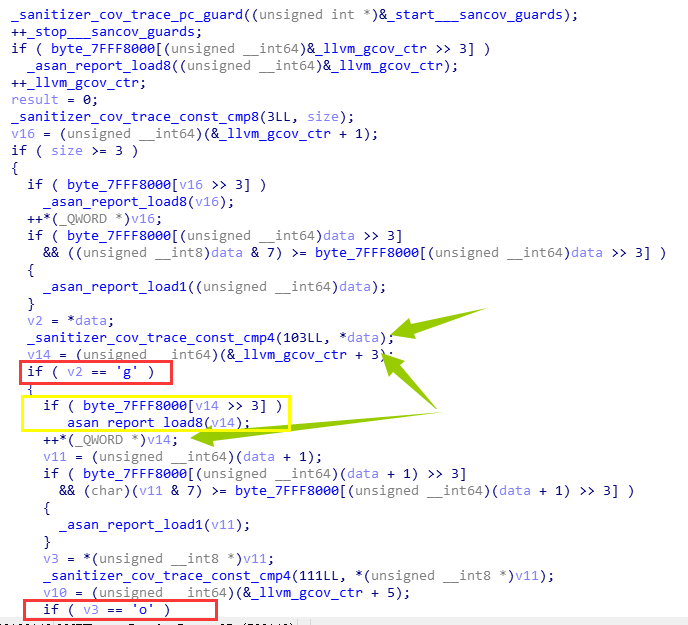
效率感觉低了很多黄色框是检测是否错误读写,0x7fff8000是一个偏移,而不是数组。
1 | //block_num是所有的block数量 |
1 | int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size); |
libfuzzer根据_sanitizer_cov_trace_const_xxx函数和 __start___sancov_cntrs数组就可以很好的 构造出适合的测试数据来访问未探索的block
1 | if (size >= 3) { |
那么简单的密码他能解决吗?便随手写了2个算法整个活
1 |
|
1 | mkdir crackme_out # fuzzer 程序可以有多个目录作为参数,此时 fuzzer 会递归遍历所有目录,把目录中的文件读入最为样本数据传给测试函数,同时会把那些可以产生新的的代码路径的样本保存到第一个目录里面。 |
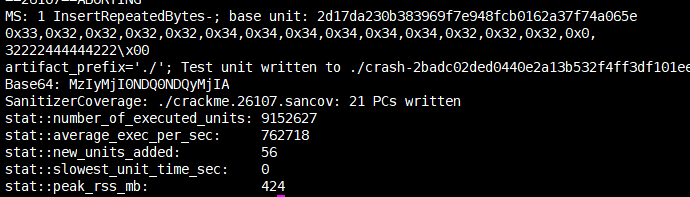
其他项目的编译方法
1 | #使用-fsanitize-coverage = trace-cmp,编译器将在比较指令和switch语句周围插入额外的工具。 |
coverage report
覆盖率就是整个fuzzer一趟测试触及的 basic-block 总个数。
文件./crackme.26107.sancov
1 | # 转换成 .symcov |
然后使用 coverage-report-server 解析这个文件。这里也有libfuzzer/lessons/08/coverage-report-server.py
1 | $ curl http://llvm.org/svn/llvm-project/llvm/trunk/tools/sancov/coverage-report-server.py -o ./coverage-report-server.py |

算法1:事实证明它还是不能解密如算法1的简单算法,更不说解循环xor :
1 | enc[i+1] = enc[i] ^ enc[i + 1]; |
原因是,它依旧不能探查前后数据的关系,几乎不可能,仅仅对一些简单条件的路径能较好的探索,一般来说足够了
1 | ./demo -help=1 #可以看到很多fuzz选项 |
移步【参考2】实战两个简单的CVE
Dictionary
就是输入的关键字合集,比如 png图片 就有 png 图片头。strcmp(phead,”xxxx”) 会直接将整个xxxx关键字替换进去,提高速度。就好比选择联想输入的候选词一样。
dictionary 文件-> google git or google afl
Dictionary 就是实现了这种思路。 libfuzzer 和 afl 使用的 dictionary 文件的语法是一样的, 所以可以直接拿 afl 里面的 dictionary 文件来给 libfuzzer 使用。
dict文件有用的只是由 "" 包裹的字串,libfuzzer 会用它们进行组合来生成样本。
1 | ./program -dict=./xxx.dict -max_total_time=300 -print_final_stats=1 input_dir |
google AFL :
1 | -x dir - optional fuzzer dictionary (see README) |
merge
可以使用 libfuzzer 把样本集进行精简。
1 | mkdir output_min_dir |
output_min_dir: 精简后的样本集存放的位置input_dir: 原始样本集存放的位置
参考&推荐:
- 基于Unicorn和LibFuzzer的模拟执行fuzzing
- fuzz实战之libfuzzer
- Dictionary
- libfuzzer-workshop
- fuzz总结
- [p1umer-2019/02/20/libfuzzer & LLVM 初探](https://p1umer.github.io/2019/02/20/libfuzzer & LLVM 初探/)