前言
代码审计存在一定的局限性,一般都是静态的检测,对于复杂的算法来说,逻辑漏洞更加难以发觉,所以需要动态的代码执行技术来进行深层次的漏洞触发
fuzz 的种类
Generation Based:通过对目标协议或文件格式建模的方法,从零开始产生测试用例,没有先前的状态Mutation Based:基于一些规则,从已有的数据样本或存在的状态变异而来Evolutionary:包含了上述两种,同时会根据代码覆盖率的回馈进行变异。
AFL
模糊测试(Fuzzing)技术作为漏洞挖掘最有效的手段之一。对整体程序进行Fuzzing
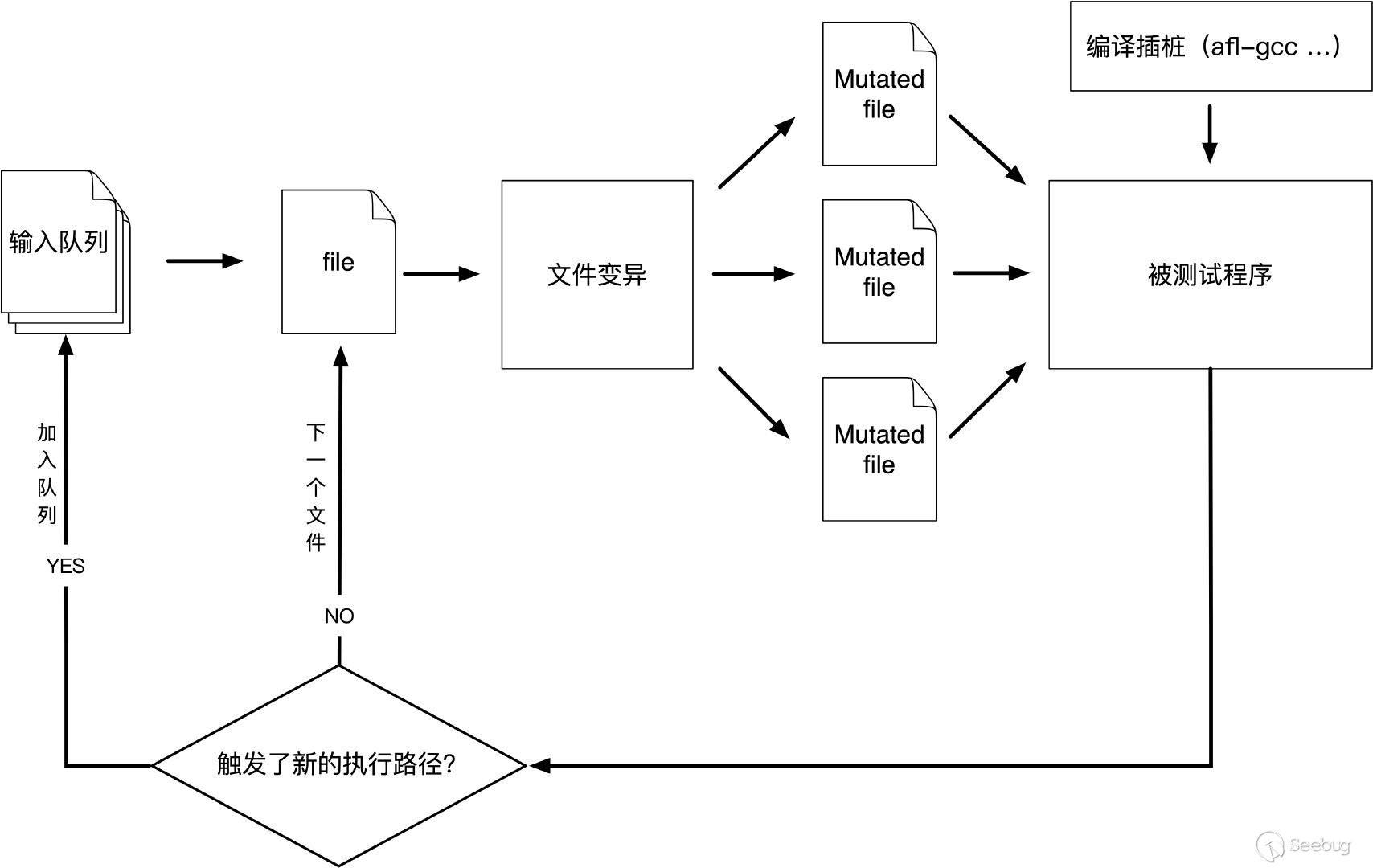
1,Build:
1 | git clone https://github.com/google/AFL.git ~/afl-src |
2,Build test target
有两种
一种是开源项目,那么直接在源码里面插桩,使用afl-clang和-clang++(其实是将编译器编译出来的汇编文件进行插桩,使用了~/afl-src/afl-as,将程序的每个block都加上回调,看下一篇AFL源码解读)
-fsanitize=address 就是开启AddressSanitizer (ASAN)内存检测工具 【参考2】
-g 产生符号,方便调试
1 | clang -g -O1 -fsanitize=fuzzer mytarget.c # Builds the fuzz target w/o sanitizers |
1 | export LLVM_CONFIG=`which llvm-config-3.5` |
另一种就是闭源程序,必须要使用QEMU 运行时动态插桩,但是效率低了。方法就是afl-fuzz命令后加上-q
1 | #不在源程序插桩的编译,且想效率高的方法,使用clang, 比gcc好多了 |
编译好的程序在 ImageMagick/utilities/.libs/magick
看下依赖情况
1 | $ ldd ./magick |
把库lnk过来
1 |
|
3,开源语料库(影响很大)
- afl generated image test sets
- fuzzer-test-suite
- libav samples
- ffmpeg samples
- fuzzdata 【推荐】
- moonshine
AFL给出的建议是最好小于1 KB,但其实可以根据自己测试的程序权衡,这在AFL文档的perf_tips.txt中有具体说明。
4,Extract
测试文件太多建议先筛选,不然太慢了
样本多样性 AFL-CMIN 移除执行相同代码的输入文件
人工增加样本多样性的方法中,最简单且明显的就是搜集下载样本,放进输入文件夹。这个过程是对样本进行丰富的过程,它非常重要,但这个过程也常常引入样本的冗余,降低fuzz的效率。为了解决这个问题,需要从大量的样本中筛掉无用的样本。
cmin操作的是文件集合,输出的也是文件集合。
可能几千个文件和f一个文件来fuzz都是一样的结果,如果不进行cmin,非常低效。
cmin也是成功使用afl-fuzz中必不可少的一步。
1 | #把所有图放一个文件夹samples里面 |
样本复杂度 AFL-TMIN 减小单个输入文件的大小
基于字长+步长的形式,逐字节删除,然后通过插装反馈得出样本改变是否导致了程序运行路径发生了变化。若没有发生变化,可以认为删去的字节是冗余的,只用于一个指定的文件。为了使每一个test case达到表示与原始测试用例相同的代码路径所需的最小值,afl-tmin遍历test case的实际字节,逐步删除很小的数据块,直到删除任意字节都会影响到代码路径表示。
tmin操作的是单个文件,输出单个文件;
对于有效地fuzzing来说,这都是很重要的步骤,也是需要理解的重要概念
1 | # instrumented mode(默认) |
5,Usage:
fuzz
1 | 下载fuzz样本集 |
白盒
执行一个单例, 测试程序的插桩
1 | afl-showmap -m none -o ./output.tuples -- ./magick convert ./jj.png cjj,jpg |
黑盒
就是使用QEMU模式,加上-Q
6,加速 SCREEN
还可以这样. 转自【参考4】

多进程
-M 参数指定一个主Fuzzer(Master Fuzzer)
-S 参数指定多个从Fuzzer(Slave Fuzzer)
Master Fuzzer进行确定性测试(deterministic )即对输入文件进行一些特殊而非随机的的变异;Slave Fuzzer 进行完全随机的变异。
我试了下,3000ms已经足够了
1 | $ screen afl-fuzz -m none -t 3000 -i ./output_tmin -o sync_dir/ -M master -- ./magick convert @@ xx3.png |
1 | 查看所有会话 |
1 | 在Session下,使用ctrl+a(C-a) |
这并不是一个很理想的解决方案,
因为这样的条件下,运行前期master fuzzer的deterministic进程太慢,而slave随机产生新的样本后,master进程的deterministic变异进程总是来不及处理;而各slave进程重复概率大,需要的同步开销过大,导致afl-fuzz的处理速度并不是线性增长。
将会在sync_dir文件夹建立master、slave1、slave2三个文件夹,三个 fuzzer各使用一个CPU。在fuzz过程中,各 fuzzer在空闲时可以读取其他文件夹中的新文件,然后对自己的queue文件进行同步和更新。
afl-whatsup 工具可以查看每个fuzzer的运行状态和总体运行概况,加上-s选项只显示概况,其中的数据都是所有fuzzer的总和。
1 | afl-whatsup sync_dir |
afl-gotcpu工具可以查看每个核心使用状态。
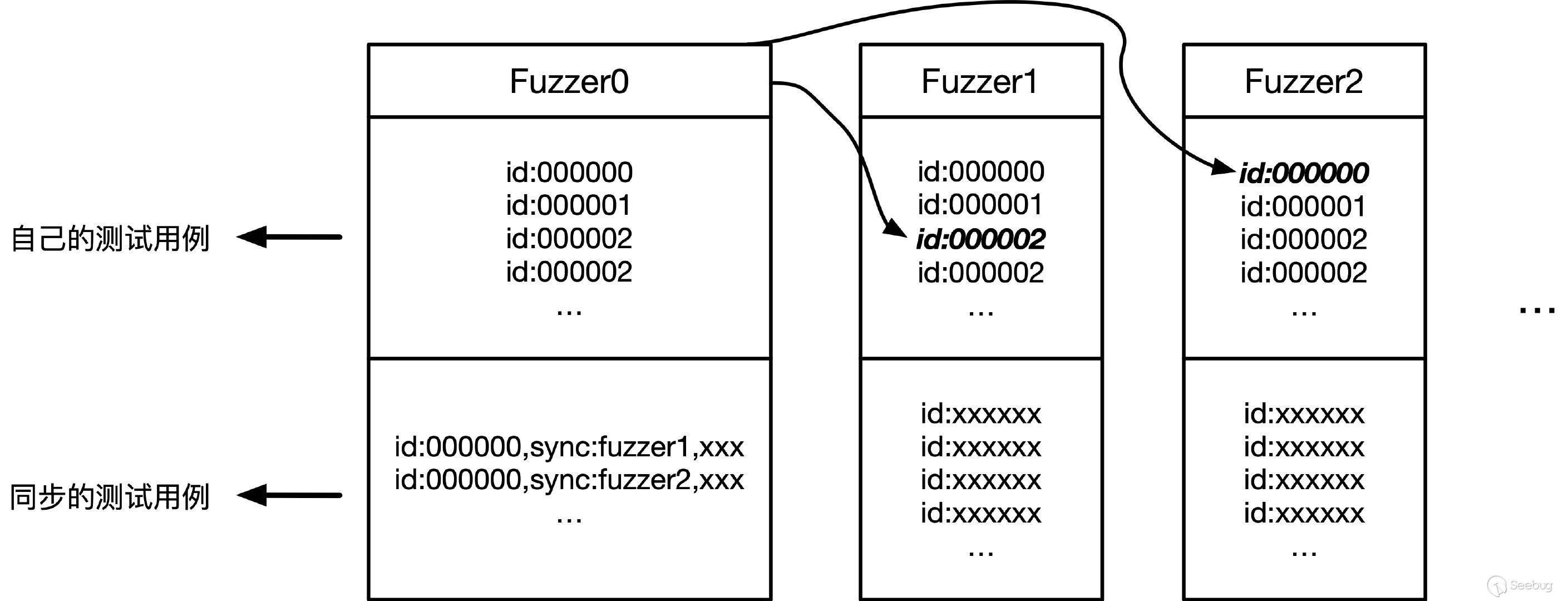
【参考1】cp“ 可以看到这里的-o指定的是一个同步目录,并行测试中所有的Fuzzer将相互协作,在找到新的代码路径时,相互传递新的测试用例,如下图中以Fuzzer0的角度来看,它查看其它fuzzer的语料库,并通过比较id来同步感兴趣的测试用例。
多系统
没有多系统先8学了
大佬方案请看【参考1】最后
7,!!! When to stop and prune !!!
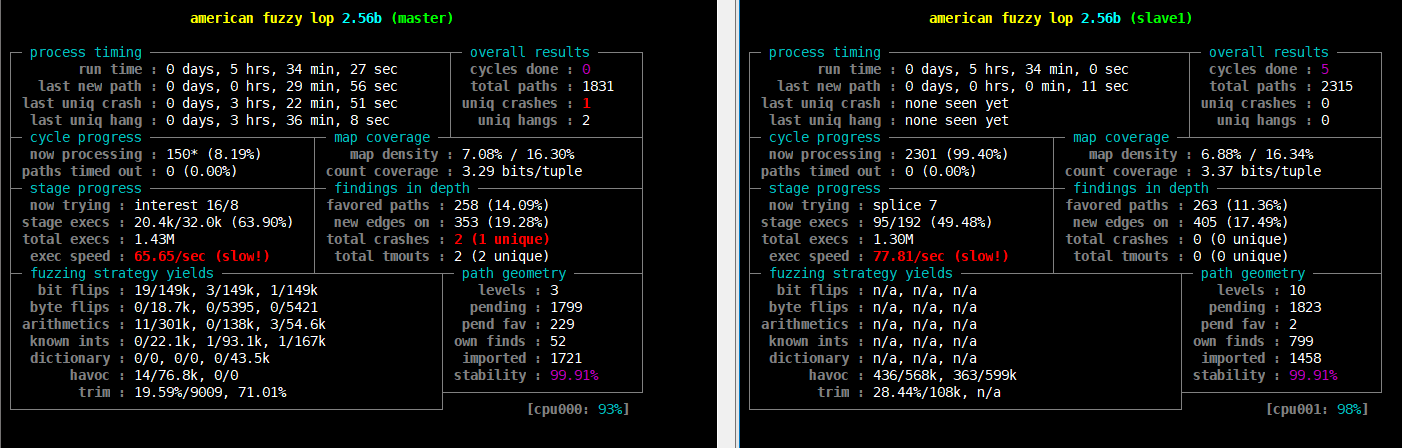
cycles done 随着周期数不断增大,其颜色也会由洋红色,逐步变为黄色、蓝色、绿色。当其变为绿色时,继续Fuzzing下去也很难有新的发现了。如上所示,fuzz程序发生异常,但是这个crash无论如何都不能触发漏洞,fuzz为什么会把它放过来?
一旦master fuzzer完成了它的第一个周期,我们可以继续并停止我们的afl-fuzz实例。我们需要合并和最小化每个实例的队列queue,并重新启动fuzzing。当使用多个fuzzing实例运行时,AFL将在根目录的syncdir目录里,根据传给afl-fuzz的参数(fuzzer的名称),为每个fuzzer维护一个独立的、同步目录。每个单独的fuzzer syncdir目录都包含一个队列queue目录,其中包含AFL能够生成的所有导致新的代码路径被检测出来的测试用例。
我们需要合并每个fuzz实例的队列目录,但是因为其中会有很多重叠,我们应该尽量最小化这个新的语料库。
1 | ls sync_dir |
一旦我们通过afl-cmin运行生成的队列,我们需要最小化每个结果文件,以使我们不在我们不需要的字节上浪费CPU周期。
贴一个大佬写的写的小bash脚本,称为afl-ptmin,它将afl-tmin并行化到一定数量的进程中,并证明在最小化过程中显著地提升了速度。
1 |
|
即使有并行化,这个过程仍然需要一段时间。完成后,从sync_dirs目录中各个fuzzer目录下删除以前的队列queue目录(/syncdirs/fuzzer1/queue/) ,然后复制**/sync_dirs/queue/**文件夹以替换旧的队列文件夹。
1 | rm -rf sync_dir/master/queue |
使用最新的最小化队列queue,我们可以在之前离开的地方继续fuzzing。
1 | screen afl-fuzz -m none -t 3000 -i- -o sync_dir/ -M master -- magick convert @@ xx1.png |
一个 -i- , 这告诉AFL只使用syncdir中的queue/目录作为该fuzzer的种子目录,然后从那里重新启动。
8,crashesdump 处理测试结果
分类
1. crash exploration mode 变异
可以快速地产生很多和输入crash相关、但稍有些不同的crashes,从而判断漏洞是否足以利用。
1 | afl-fuzz -m none -C -i poc -o peruvian-were-rabbit_out -- ~/src/LuPng/a.out @@ out.png |
2.triage_crashes 信号量判断
11代表了SIGSEGV信号,有可能是因为缓冲区溢出导致进程引用了无效的内存;
06代表了SIGABRT信号,可能是执行了abort\assert函数或double free导致;
….后面再收集
1 | ~/afl-src/experimental/crash_triage/triage_crashes.sh fuzz_out program @@ 2>&1 | grep SIGNAL |
3:crashwalk
#build
1 | apt-get install gdb |
#use
crashwalk支持AFL/Manual两种模式。
#Manual Mode
1 | ~/tools/go/bin/cwtriage -root syncdir/master/crashes/ -match id -~/program @@ |
#AFL Mode 读取crashes/README.txt文件获得目标的执行命令
1 | ~/tools/go/bin/cwtriage -root syncdir -afl |
4:afl-collect
项目地址: https://github.com/rc0r/afl-utils
它是afl-utils套件中的一个工具,同样也是基于exploitable来检查crashes的可利用性。
它可以自动删除无效的crash样本、删除重复样本以及自动化样本分类
1 | git clone https://github.com/rc0r/afl-utils |
1 | afl-collect -j 8 -d crashes.db -e gdb_script ./sync_dir ./collection_dir -- /path/to/target --target-opts |
还有其他很多功能多留意,后面我再来补充
afl-collectafl-cronafl-minimize afl-multicore afl-multikillafl-statsafl-syncafl-vcrash
5:手动看异常 (AddressSanitizer )(ASAN)
我们上面编译测试程序编译就开了ASAN,可以很好的分析展示出错误
1 | ./magick convert crash/xxxxxxx output |
9,code coverage 代码覆盖率
由于不能量化在二进制文件中执行可用的代码路径的程度,你会丢失很多信息。通过确定你没有到达代码库的哪些部分,你可以更好地调整你的测试用例种子,以便于达到更高的测试完整度。
- 工具之一是GCOV,它随gcc一起发布,所以不需要再单独安装,和afl-gcc插桩编译的原理一样,gcc编译时生成插桩的程序,用于在执行时生成代码覆盖率信息。
- 另外一个工具是LCOV,它是GCOV的图形前端,可以收集多个源文件的gcov数据,并创建包含使用覆盖率信息注释的源代码HTML页面。
- 最后一个工具是afl-cov,也是一个python脚本,可以快速帮助我们调用前面两个工具处理来自afl-fuzz测试用例的代码覆盖率结果。
1 | apt-get install lcov |
一,CFLAGS中添加"-fprofile-arcs"和"-ftest-coverage"选项,--prefix指定一个新的目录。
1 | cd ~/xxx/build/ |
二,有了新程序,afl-cov可以将在给定输入的二进制程序中采用的代码路径与文件系统上的代码库链接起来。执行afl-cov。当afl-fuzz停止时,afl-cov将退出
1 | AFL_FILE和afl中的”@@”类似 |
完成后,afl-cov在sync_dir目录下的名为cov的目录中生成报告信息。 其中包括可以在Web浏览器中轻松查看的HTML文件,详细说明命中了哪些函数和哪行代码,以及未命中的函数和代码行。
当然使用afl去fuzz chrome, 如v8引擎的js编译基本可以放弃了,因为就简单的关键字function ,那要产生多少err才能通过啊。几乎不太可能去生成有效的js语法,会卡在语法parser那里。
参考&推荐:
Fuzzing-ImageMagick (魔鬼!不到2天光爆破一个程序就十几个cve !)
AFL-FUZZ暴力效率流实践 大佬对fuzz进行了改造,值得深究嗷
SanitizerCoverage clang的官方文档,讲了本节很多要了解的编译参数
这些项目必学一下,afl官方停止更新了
winafl、afl-go、WinAFL、afl-cov、kafl、android-afl