1 | 172.16.9.52 9W8K#J7v 22/8888 5032/6032 |
Heap
- • dlmalloc – General purpose allocator
- • ptmalloc2 – glibc
- • jemalloc - FreeBSD and firefox
- • tcmalloc – Google
- • libumem - Solaris
ptmalloc
Ubuntu16:
- libc6_2.23-0ubuntu11.2_amd64
- libc6_2.23-0ubuntu11.2_i386
Ubuntu18:
- libc6_2.27-3ubuntu1.3_amd64
- libc6_2.27-3ubuntu1.3_i386
32
1 | 无 |
64
chunksize = 0x180 则malloc( ( 0x180 - 24, 0x180 - 8 ] )
堆块块(Chunk), 其头部保存着自身的大小等信息, 在这之后即 是用户数据。一共有 3 种类型, 它们都使用同一种数 据结构(malloc_chunk)定义。
1 | struct malloc_chunk { |
具体来说, 用于管理的堆块主要分为 3 种类型。
Allocated Chunk: 已分配块

Free Chunk: 被释放块

Top Chunk: 顶块
位于所有块之后, 保存着 未分配的所有内存, 与已分配块使用相同的域。
glibc 使用 size 域的最低 3 位来 存储一些其它信息。相关的掩码信息定义如下:
1 |
1 | pwndbg> arena <- main_arena |
Bins:
Fast Bins:
单向链表
每个元素是一 条单向链表的头部
且同一条链表中块的大小相同。 主要保存大小 32 至 128 字节的块 (0x20 - 0x80). malloc(0-0x78)
特点是当 free 时 不取消下一块的 PREV_INUSE 位, 也不检查是否能 够进行合并操作
Fast bins 的取用机 制是 LIFO (Last In First Out) , 即后释放的块将先被利用。(从fastbin头开始存和取)修改 fd
Free 1 2 3 M 3 2 1
链无数量限制
Unsorted Bins
从头开始插入, 从尾部解链分配
之后的 Small Bins 与 Large Bins 也是同样的机制。
1 | bins = {0x602120, 0x602000, 0x7ffff7dd1b88 <main_arena+104>, 0x7ffff7dd1b88 <main_arena+104>,...} |
Small Bins:
- 每个元素是一 条双向循环链表的头部
- 且同一条链表中块的大小相同。
- 主要保存大小 32 至 1024 字节的块。
- 由于是 双向链表, Small Bins 的取用机制是 FIFO (First In First Out) , 即先释放的块会先被利用,
- Free 1 2 3 M 1 2 3
Large Bins
- 每个元素是一条 双向循环链表的头部
- 同一条链表中块的大小不一 定相同
- 按照从大到小的顺序排列
- 每个 bin 保存一定 大小范围的块, 主要保存大小 1024 字节以上的块。
malloc流程
#假设malloc一个0x80的块)
malloc hook指针
在第一次执行malloc函数时, 系统会使用brk系 统调用向操作系统扩展程序的数据区, 此时 glibc 将 初始化top chunk与main_arena, 取得132KB的空间。 如果之后所有的 malloc 操作都可以满足, 即最后总 是能在此 132KB 中找到合适的内存块返回, 则不再 使用系统调用与内核交互。这段时间, 程序的堆内存 由 glibc 管理。glibc 首先将其加上 8 字节的额外开销,再对齐32字节。
检查 Fast bins 如果请求大小满足 Fast bins, 则在对应的 bin 中 寻找是否有相同大小的块, 如果有则直接将其取出 返回给程序, 同时更新 fast bins 中对应 bin 存储的链 表头指针
检查 Small bins 如果块大小符合 Small bins, 则在对应大小的 Small bin 中寻找是否有合适的块, 如果有则直接返 回, 同时更新 Small bins 中对应 bin 的链表中该块的 上一块和下一块的指针。
处理 Unsorted bin 如果之前没能返回恰好符合的块, 则开始处理 Unsorted bin 中的块(这里有一个例外, 如果 Unsorted bin 中只有一个块且这个块是 last_remainder, 而且大 小足够, 则优先使用此块, 分裂后将前一块返回给 用户, 剩下的一块作为新的 last_remainder 再次放入 Unsorted bin.[7])
- a) 逐个迭代Unsorted bin中的块, 如果发现块的 大小正好是需要的大小, 则迭代过程中止, 直接返 回此块;否则将此块放入到对应的 Small bin 或者 large bin 中, 这也是整个 glibc 堆管理中唯一会将块 放入 Small bins 与 large bins 中的代码。
- b) 迭代过程直到 Unsorted bin 中没有块或超过 最大迭代次数(10000)为止。
- c) 随后开始在 Small bins 与 large bins 中寻找最 合适的块(指大于请求大小的最小块), 如果能够找到, 则分裂后将前一块返回给用户, 剩下的块放入 Unsorted bin 中。
- d) 如果没能找到, 则回到开头, 继续迭代过程, 直到 Unsorted bin 空为止 2.2.4 使用顶块 如果之前的操作都没能找到合适的块, 将分裂 Top chunk 返回给用户, 若 Top chunk 的大小仍然不 足, 则再次执行 malloc_consolidate 函数清除 Fast bins, 若Fast bins已空, 只能使用sysmalloc函数借助 系统调用拓展空间。
free流程
- Free 函数是 glibc 的释放接口, 将之前分配得到 的用户内存指针作为参数, glibc 会释放这一块空间。 主要的功能由_int_free 函数实现。
- 首先, 进行一系列的检查, 包括内存地址对齐, PREV_INUSE 位是否正确等等, 能够发现一些破坏 与 double free 的问题。
- 如果块大小满足 Fast bins, 则不取消下一块的 PREV_INUSE 位, 也不设置下一块的 prev_size 域, 直接将该块放入对应的 Fast bin 中, 且不进行相邻块 的合并操作。
- 检查被 free 内存块的前一块(这里的前一块指连 续内存中的上一块, 通过 prev_size 域来寻找), 如果 未使用, 则合并这 2 块, 将前一块从其 bin 中移除之 后再检查其后一块, 如果发现是 Top chunk, 则最后将 合并到 Top chunk 中, 不放入任何 bin; 如果不是 Top chunk 且未使用, 则再合并这 2 块, 将后一块从其 bin 中移除, 并且将合并过的大块放入 Unsorted bin 中。
heap伪代码
1 | void* find_from_fastbin(int idx){ |
unlink Attack
1 |
|
Fastbin_attack
1 |
The House of Prime glibc [2.3.5 - 2.19)
此方法是利用 glibc 在判断 Fast Bins 的下标时的 一个疏忽来破坏main_arena中的数据, 在早期的glibc 2.3.5 版本中, main_arena 结构与现在有所不同:
1 | struct malloc_state { |
而 glibc 在根据块大小取得 Fast bins 数组下标时 使用的宏如下面所示:
#define fastbin_index(sz) ((((unsigned int)(sz)) >> 3) - 2)
若此时的 sz 为 8, 则最后得到的下标为 (8 >> 3) – 2 = –1, 这就意味着若溢出时将下一块的 sz 修改为 8,则会造成 fastbins 数组的上一个域即 max_fast 变量遭到破坏。
但在glibc 2.19版本中, main_arena的结构已经 发生了变化, 虽然 fastbin_index 宏仍然存在漏洞, 但 在 fastbins 数组的前面不再是 max_fast 变量, 此变量 被移出结构体作为全局变量 global_max_fast 使用, 这样一来, 通过破坏前一个域来进行利用的方法已 不可行。
The House of Mind. [当前流行的 glibc 中已不再可行]
此方法在当前流行的 glibc 中已不再可行, glibc 在 free 时都需要对 Unsorted bin 进行检查, 确认其中 的第一个块的后向指针是否指向自身, 如此一来若 攻击者将 Unsorted bin 指向希望控制的内存区域, 则 会导致检查失败而无法利用。
The House of Force 【需要进行heap泄露】
此方法通过溢出Top chunk的size域来欺骗glibc, 使得攻击者 malloc 一个很大的数目(负有符号整数) 时能够使用 Top chunk 来进行分配, 此时 Top chunk 的位置会加上这个大数, 造成整数溢出, 结果是 Top chunk 能够被转移到堆之前的内存地址(如程序的.bss 段, .data 段, GOT 表等), 下次再执行 malloc 时, 就会 返回转移之后的地址, 攻击者即能够控制其他的内 存数据。
32为例子
攻击者溢出 Top chunk 的上一块, 将 Topchunk 的大小修改为 0xffffffff。
攻击者需要能够控制下一次 malloc 时传入的
大小, 此时传入 0xffffffec, 经过处理得到的大小是 0xfffffff0, glibc 的大小使用的是 size_t 类型存储, 这 是一种与机器字长相等的无符号整形。故此时 glibc 认为 0xffffffff > 0xfffffff0, 即 Top chunk 的空间足够, 于是使用 Top chunk 进行分配。假设 Top chunk 之前 的位置是 0x804a010 分配后, Top chunk 的地址将处 于 0x804a010 + 0xfffffff0 = 0x804a000。
下次 malloc 时, 攻击者就能够取得 0x804a000 这块内存, 进一步修改就能够干扰程序的运行。
此方法的缺点在于, 会受到之后提到的 ASLR 技术的影响, 如果攻击者需要修改指定位置的内存, 他需要知道当前 Top chunk 的位置以构造合适的 malloc 大小来取得对应的内存。而 ASLR 开启时, glibc 的堆内存地址将会是随机的, 如果想要利用此 项技术, 则需要进行信息泄露。
The House of Lore 【可行】
glibc 2.19也可使用,需绕过
此方法希望通过破坏已经放入 Small bins 中块 的 bk 指针来达到取得任意地址的目的
在早期的 glibc 2.3.5 版本的_int_malloc 中, 处理 Small Bins 的 代码如下所示:
1 | //参考上面的 find_from_smallbin |
即如果请求的大小符合 Small Bins, 则在对应的 bin 中寻找是否有空闲的块, 如果有就直接从 bin 的 链表中解链并返回给用户。
基于上面的机制, 当一个块存在于 Small Bin 的 第一个块(这里的第一块指的是在取 Small Bin 块时 选择的第一块, 即 Small Bin 的 bk 指针指向的那一块) 时, 通过溢出修改其 bk 指针指向某个地址 ptr, 当下 一次 malloc 对应大小的块时, 就有 bck = victim->bk= ptr, 且 bin->bk = bck = ptr, 这样以来就成功地将这 个 bin 的第一块指向了 ptr, 下次再 malloc 对应大小 就能够返回 ptr+16 的位置了, 这样攻击者再对取回 的块进行写入就能控制 ptr+16 的内存内容。
尽管在 glibc 2.19 版本的代码中, 已经加入了对 应的防御机制, 通过检查 bin 中第二块的 bk (我感觉是fd) 指针是 否指向第一块, 可以发现对 Small bins 的破坏。但攻 击者如果同时伪造了 bin 中的前 2 块(smallbin->bk->bk->fd == smallbin->bk), 就可以绕过这 个检查。故此种利用方式仍然可以进行。
The House of Spirit [fastbins attack]
此方法通过堆的Fast bin机制来辅助栈溢出的利 用, 一般的栈溢出漏洞的利用都希望能够覆盖函数 的返回地址以控制 EIP 来劫持控制流, 但若栈溢出 的长度无法覆盖返回地址, 但是能够覆盖到栈上的 一个即将被 free 的堆指针, 此时可以将这个指针改 写为栈上的地址并在相应位置构造一个 Fast bin 块的 元数据。接着在 free 操作时, 这个栈上的“堆块”即 被投入 Fast Bin 中, 下一次 malloc 对应的大小时, 由 于 Fast Bin 的机制为先进后出, 故上次 free 的栈上的 “堆块”能够被优先返回给用户, 再次写入时就可能 造成返回地址的改写, 亦可进行信息泄漏。
此方法的缺点与The House of Force方法类似, 需要对栈地址进行泄漏, 否则无法正确覆盖需要释 放的堆指针, 且在构造数据时, 需要满足对齐的要 求, 存在很多的限制。
现代保护手段NX ALSR PIE RELRO
- 不可执行位 NX Bit
- 地址空间布局随机化 ASLR
- 位置无关可执行文件 PIE
- 重定位只读 RELRO
- 部分 RELRO: 在程序装入后, 将其中一些段 (如.dynamic)标记为只读, 防止程序的一些重定位信 息被修改。
- 完全 RELRO: 在部分 RELRO 的基础上, 在 程序装入时, 直接解析完所有符号并填入对应的值, 此时所有的 GOT 表项都已初始化, 且不装入 link_map 与_dl_runtime_resolve 的地址(二者都是程 序动态装载的重要结构和函数)。
堆的攻击手段
- 现代利用手段
- 现代解链操作 UNLINK 攻击当前的glibc对unlink宏进行了 加固, 传统的 unlink 利用方法已不再可行。为了绕过 当前的 glibc 对 unlink 做的检查, 需要在内存中找到 指向构造的伪块的指针
- 攻击 Fast bins
- 释放后使用漏洞的利用
- 两次释放漏洞的利用 double-free
- 改写 Realloc Hook
- 利用单字节溢出漏洞
- 扩展被释放块
- 扩展已分配块
- 收缩被释放块
- 攻击 Unsorted Bin
- 重分配函数的利用
double free
1 | free(a) |
__realloc_hook [fastbin attack]
__realloc_hook 在程序启动时有一个非 0 的初 始化值, 在 64 位系统中, 这个地址将以 7f 开头
攻击者能够通过刻意的内存地址错位来进行 Fast Bin Attack, 从而达到改写__realloc_hook 的目的。
1 | 0x7ffff7dd3798 <_IO_stdfile_0_lock+8>: 0x0000000000000000 0x0000000000000000 |
Off-by-one 单字节溢出漏洞
通过溢出下一个块的size域,攻击者能够在堆中创造出重叠的内存块
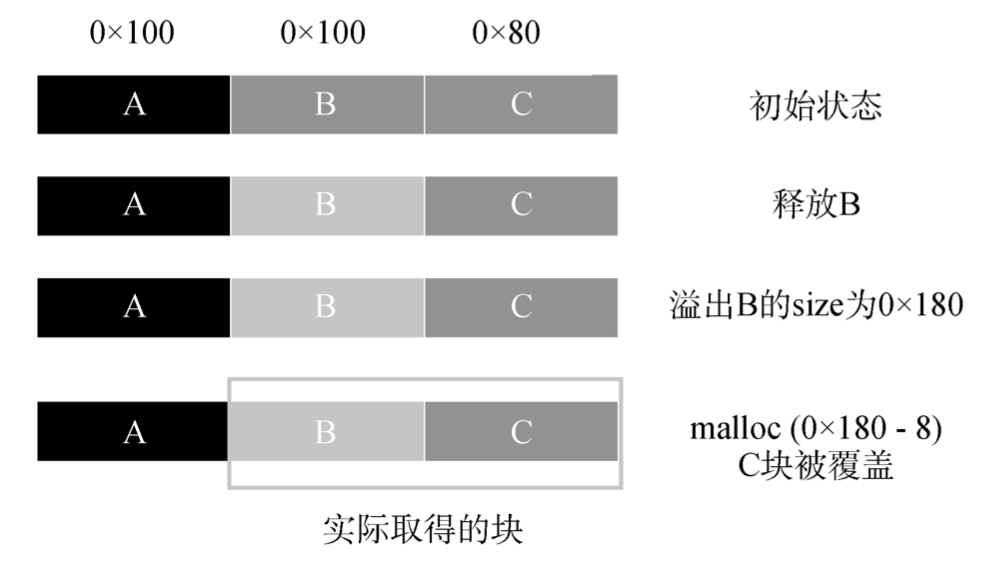
扩展被释放块
若溢出块的下一块为被释放的块且处于Unsorted Bin 中, 则可以通过溢出一个字节来将其大 小扩大, 下次取得此块时就意味着其后的块将被覆 盖而造成进一步的溢出。
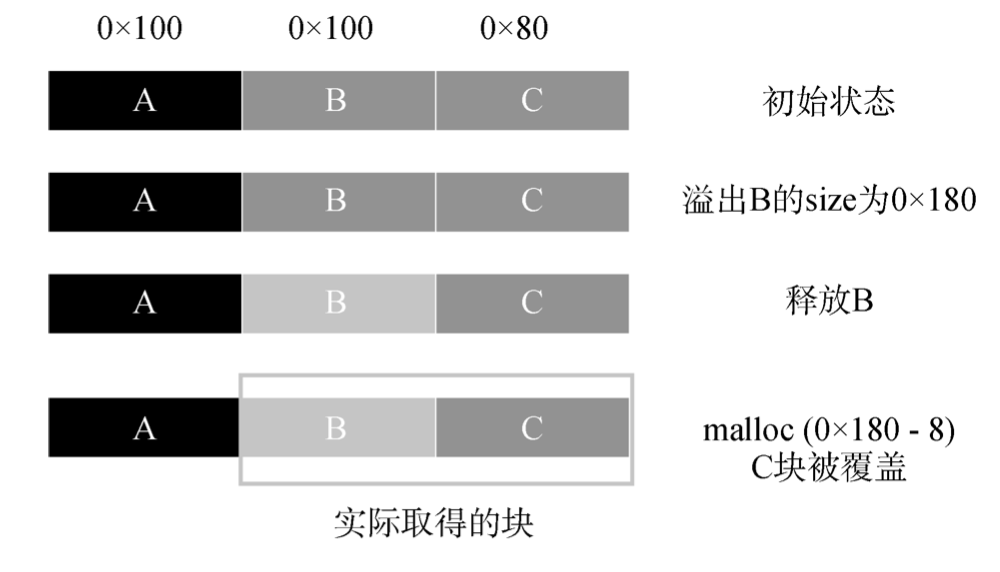
扩展已分配块
若溢出块的下一块为使用中的块, 则需要合理 控制溢出的字节, 使其被释放时的合并操作能够顺 利进行, 例如直接加上下一块的大小使其完全被覆 盖。下一次分配对应大小时, 即可取得已经被扩大的 块, 并造成进一步溢出。
收缩被释放块
此情况针对溢出的字节只能为 0 的情况, 此时
可以将下一个被释放块的大小缩小, 如此一来在之 后分裂此块时将无法正确更新后一块的 prev_size 域,导致释放时出现重叠的堆块。

B2为fasten
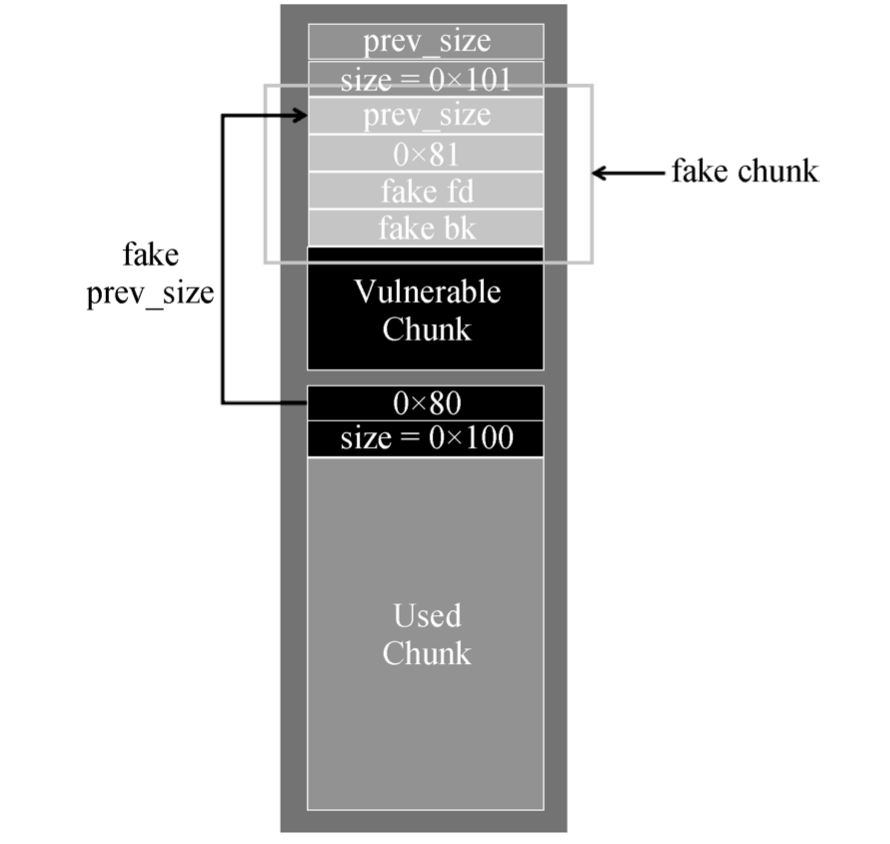
The House of Einherjar
此方法也是针对溢出字节只能为 0 的情况, 利 用的思路是不将溢出块下一块的大小缩小, 而是仅 仅更新后一块的 prev_size 域, 使其在被释放时能够 找到之前一个合法的被释放块并与其合并, 造成堆 块的重叠
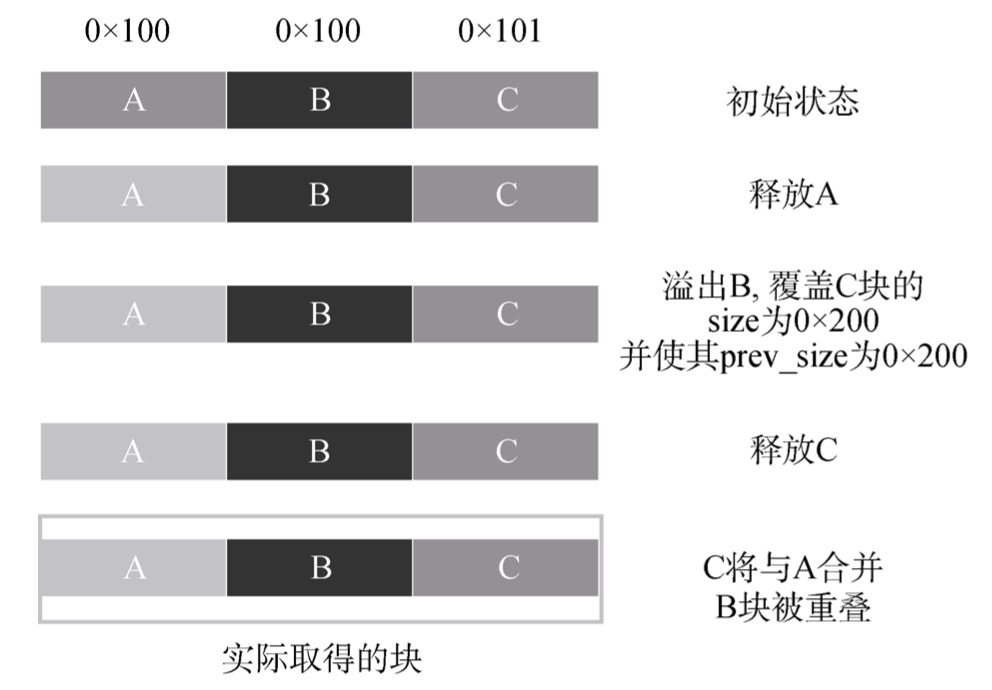
1 | C->prev_size = 0x200 |
成功后的利用方式
malloc包含已释放块
如果是fastbin那就简单
malloc包含已分配块
攻击 Unsorted Bin [可le a k]
当 Unsorted Bin 中的块恰好为分配的块大小时
则会直接从 Unsorted Bin 中移除 返回给用户。若不是, 则将其投入对应的 Bin 之中。
无论结果如何, 其最终都将从 Unsorted Bin 中移除, 而这里移除使用的方法并不是 2.3 节中释放操作使 用的 unlink 宏, 而是如下代码:
1 | bck = victim->bk; |
不同于 unlink 宏, 这里对 Unsorted Bin 的链表完 整性并没有做检查, 导致如果能够可以修改某一个 处于 Unsorted Bin 中的块的 bk 指针, 则可以造成一 个任意内存写入, 可以将 bk + 16 的位置改写为 Unsorted Bin 的地址, 但 Unsorted Bin 的 bk 指针将被 破坏, 下一次再使用 Unsorted Bin 时, 将可能由于 bck 的位置不可写而造成程序崩溃。
Leak: 如果last->bk = ptr, 则malloc后, ptr->fd = unsorted_bin, 可以直接泄漏ptr->fd, 且无检查
2.29 tcache 【无le a k】
tcache全称thread local caching,是glibc2.26后新加入的一种缓存机制(在Ubuntu 18及之后的版本中应用),提升了不少性能,但是与此同时也大大牺牲了安全性,在ctf-wiki中介绍tcache的标题便是tcache makes heap exploitation easy again,与fastbin非常相似但优先级高于fastbin,且相对于fastbin来说少了很多检查,所以更加便于进行漏洞利用。
- 可直接double free
tcache 和 fastbin在free中并没有被清除inuse标志
tcache机制的主体是tcache_perthread_struct结构体,其中包含单链表tcache_entry
单链表tcache_entry,也即tcache Bin的默认最大数量是64,在64位程序中申请的最小chunk size为32,之后以16字节依次递增,所以size大小范围是0x20-0x410,也就是说我们必须要malloc size≤0x408的chunk
每一个单链表tcache Bin中默认允许存放的chunk块最大数量是7
在申请chunk块时,如果
tcache Bin中有符合要求的chunk,则直接返回;如果在fastbin中有符合要求的chunk,则先将对应fastbin中其他chunk加入相应的tcache Bin中,直到达到tcache Bin的数量上限,然后返回符合符合要求的chunk;
如果在smallbin中有符合要求的chunk,则与fastbin相似,先将双链表中的其他剩余chunk加入到tcache中,再进行返回
在释放chunk块时,如果chunk size符合tcache Bin要求且相应的tcache Bin没有装满,则直接加入相应的tcache Bin
与fastbin相似,在tcache Bin中的chunk不会进行合并,因为它们的
pre_inuse位会置成1
1 | idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit) 16 |
tcache机制允许将空闲的chunk以链表的形式缓存在线程各自tcache的bin中。
下一次malloc时可以优先在tcache中寻找符合的chunk并提取出来。
他缺少充分的安全检查,如果有机会构造内部chunk数据结构的特殊字段,我们可以有机会获得任意想要的地址。
1 | static void |
file:///Users/notify/ctf-wiki/site/pwn/linux/glibc-heap/tcache_attack-zh/index.html
References
• http://phrack.org/issues/58/4.html
• http://acez.re/ctf-writeup-hitcon-ctf-2014-stkof-or-modern-heap-overflow/
Glibc Adventures: The Forgotten Chunks,
• https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/