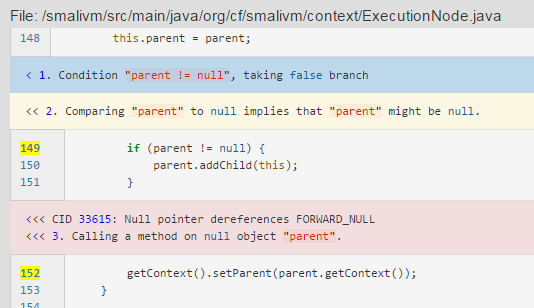
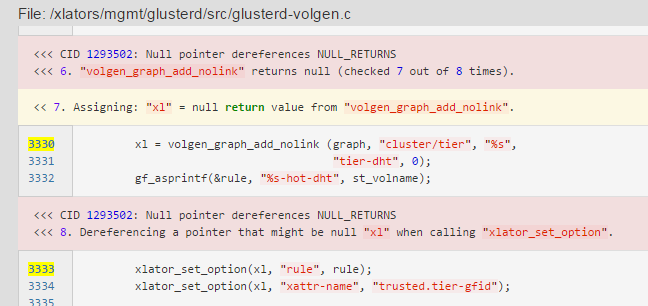
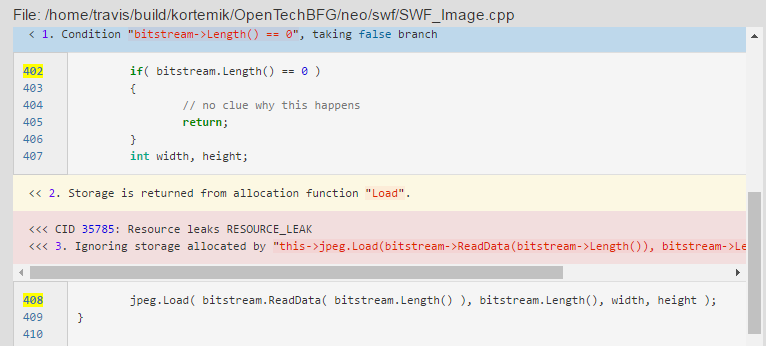
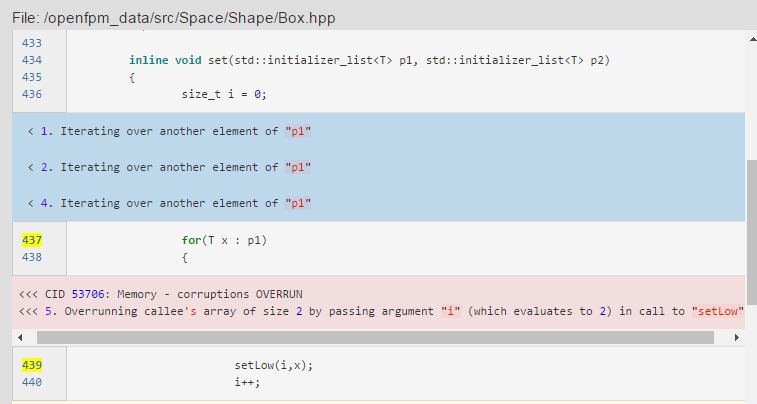
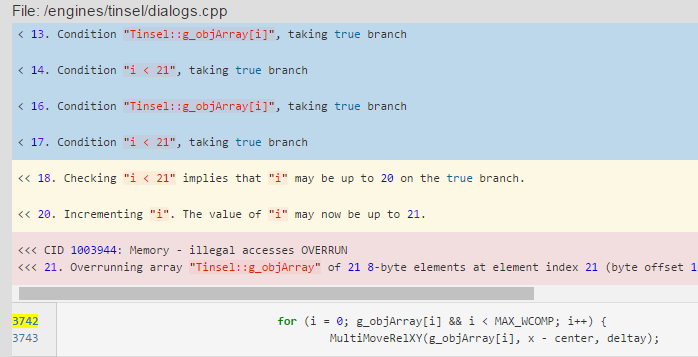
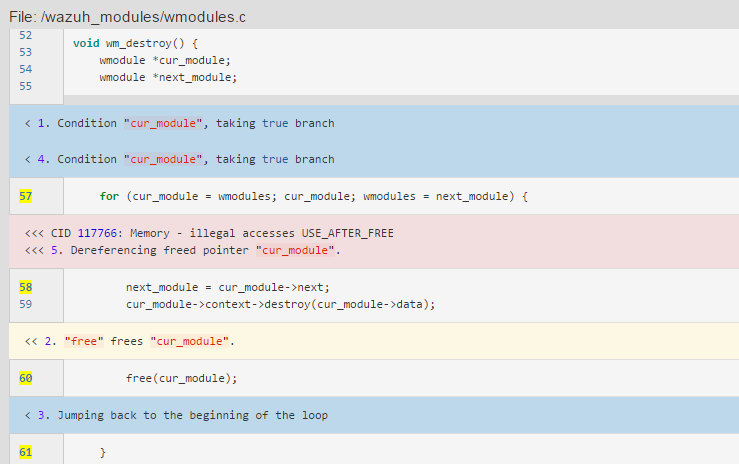
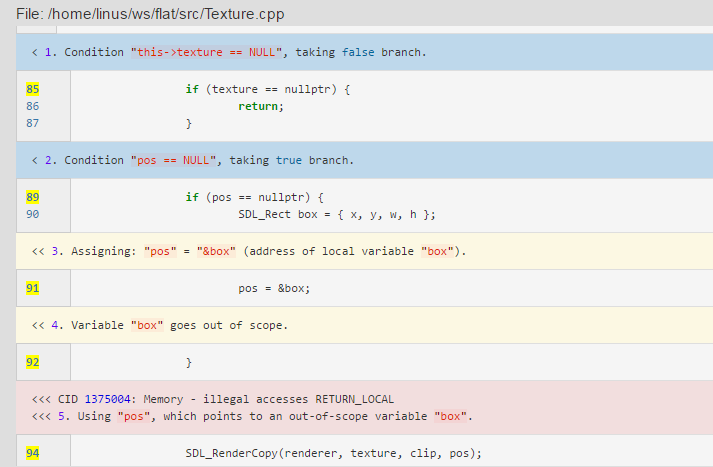
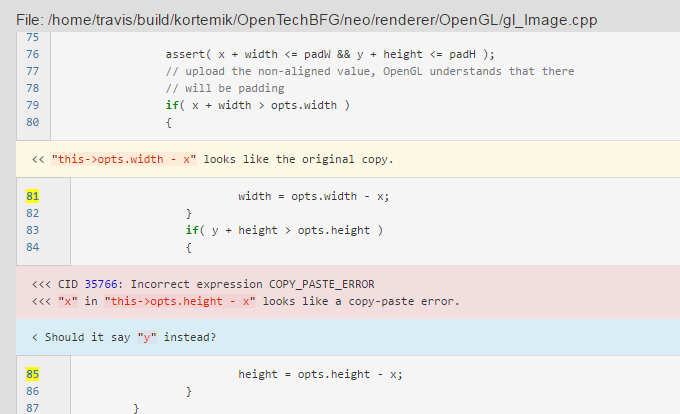
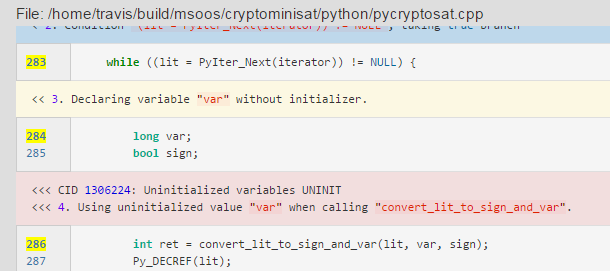
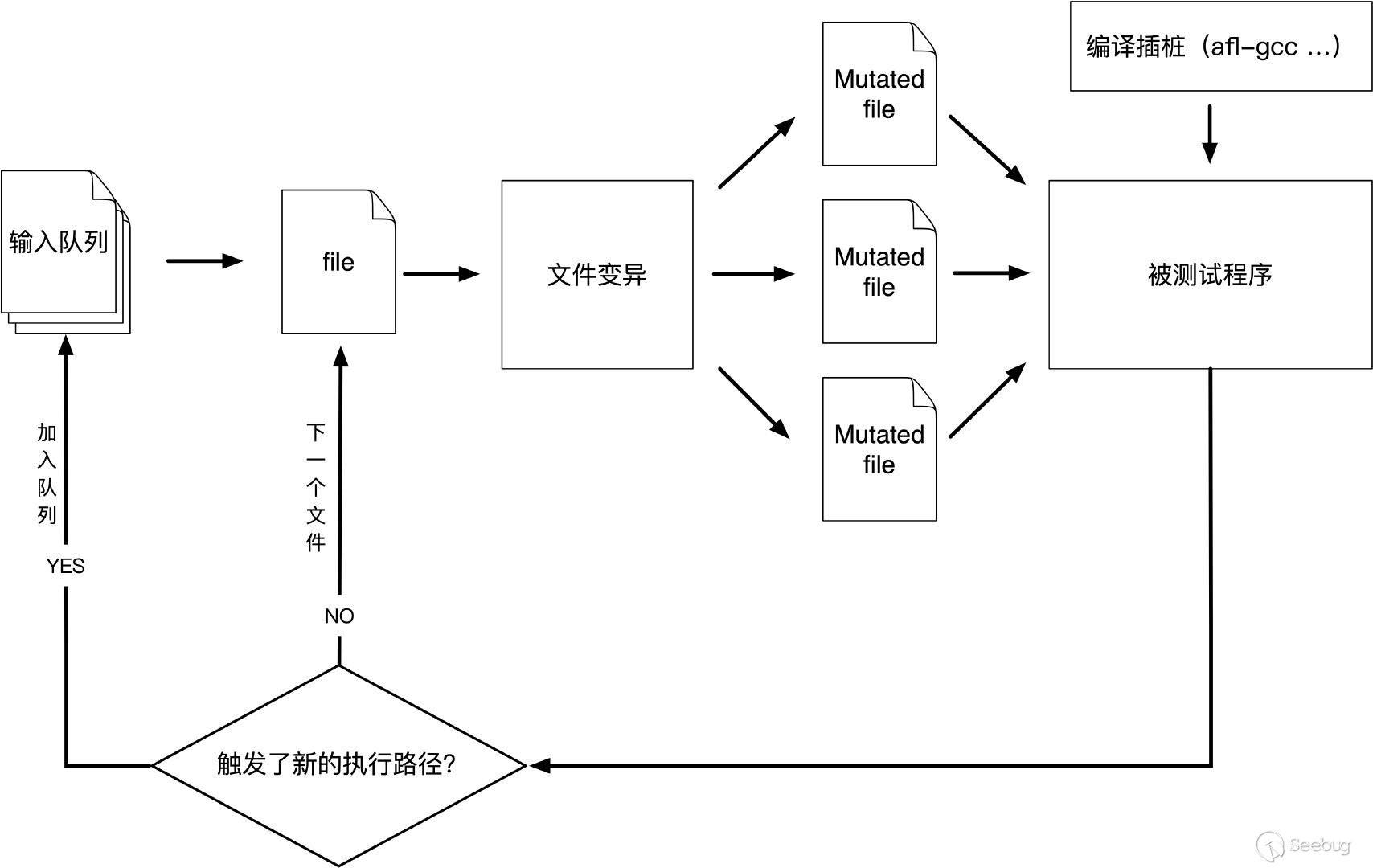
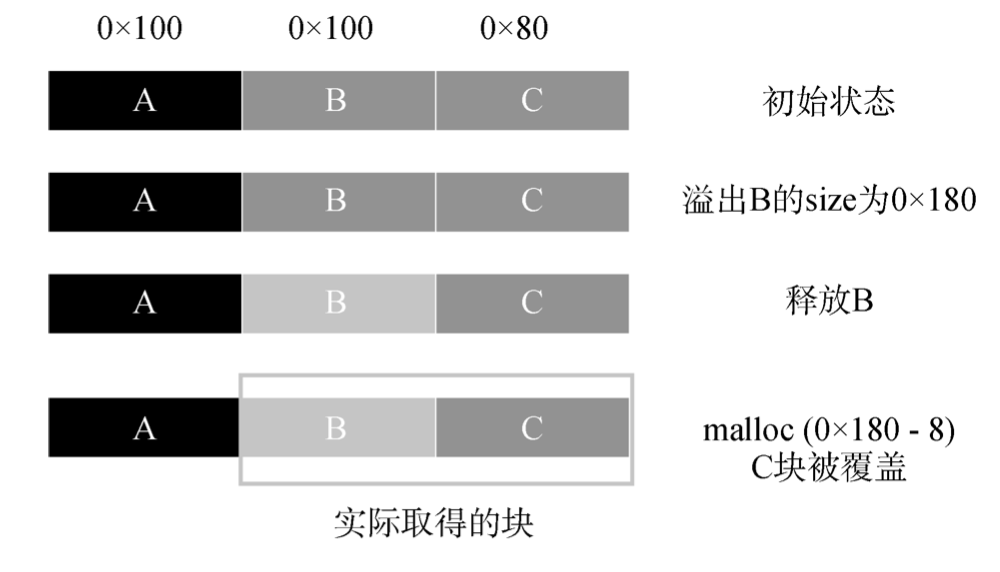
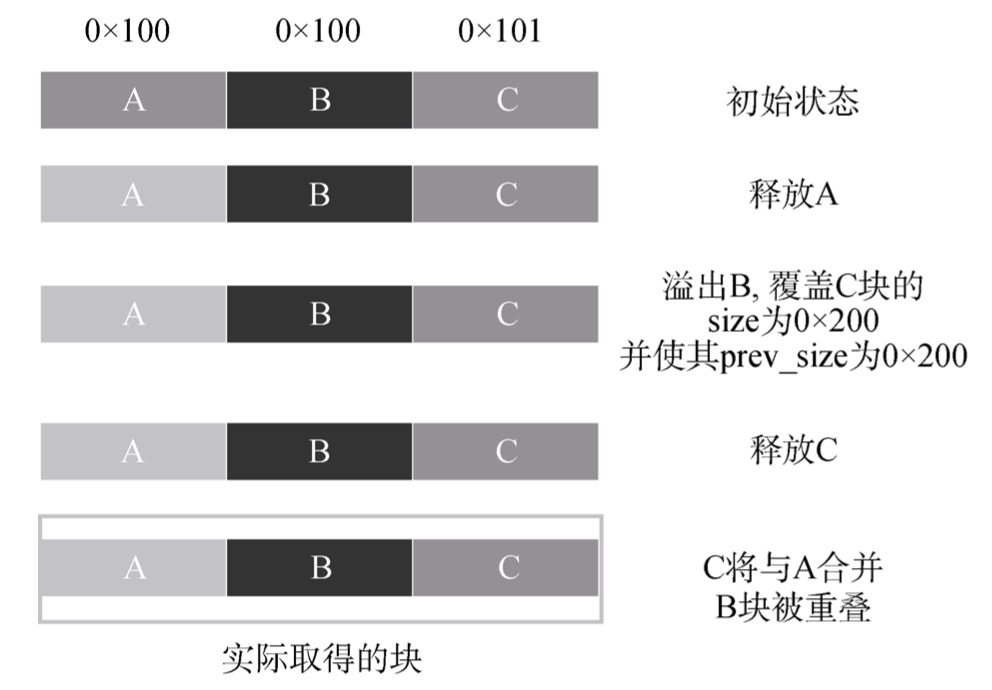
我写xmind上了无法展示就先贴着
代码保护技术

反调试
调试器状态检测
winAPI
· Bool CheckRemoteDebuggerPresent()
· Bool IsDebuggerPresent()
PEB的BeingDebugged标志位
bool PebIsDebuggedApproach()
{
char result = 0;
__asm
{
// 进程的PEB地址放在fs:[30h]
mov eax, fs:[30h]
// 查询BeingDebugged标志位
mov al, BYTE PTR [eax + 2]
mov result, al
}
return result != 0;
}
PEB.NtGlobal
bool PebNtGlobalFlagsApproach()
{
int result = 0;
__asm {
// 进程的PEB
mov eax, fs:[30h]
// 控制堆操作函数的工作方式的标志位
mov eax, [eax + 68h]
// 操作系统会加上这些标志位FLG_HEAP_ENABLE_TAIL_CHECK,
// FLG_HEAP_ENABLE_FREE_CHECK and FLG_HEAP_VALIDATE_PARAMETERS,
// 它们的并集就是x70
//
and eax, 0x70
mov result, eax
}
return result != 0;
}
PEB.ProcessHeap.ForceFlags
bool HeapFlagsApproach()
{
int result = 0;
__asm
{
// 进程的PEB
mov eax, fs:[30h]
// 进程默认的堆
mov eax, [eax + 18h]
// 检查ForceFlag标志位
mov eax, [eax + 10h]
mov result, eax
}
return result != 0;
}
PEB.ProcessHeap.Flags
// PEB.ProcessHeap
mov eax, dword ptr [ebx+18h]
cmp dword ptr [eax+0ch] == 2
nt内核函数
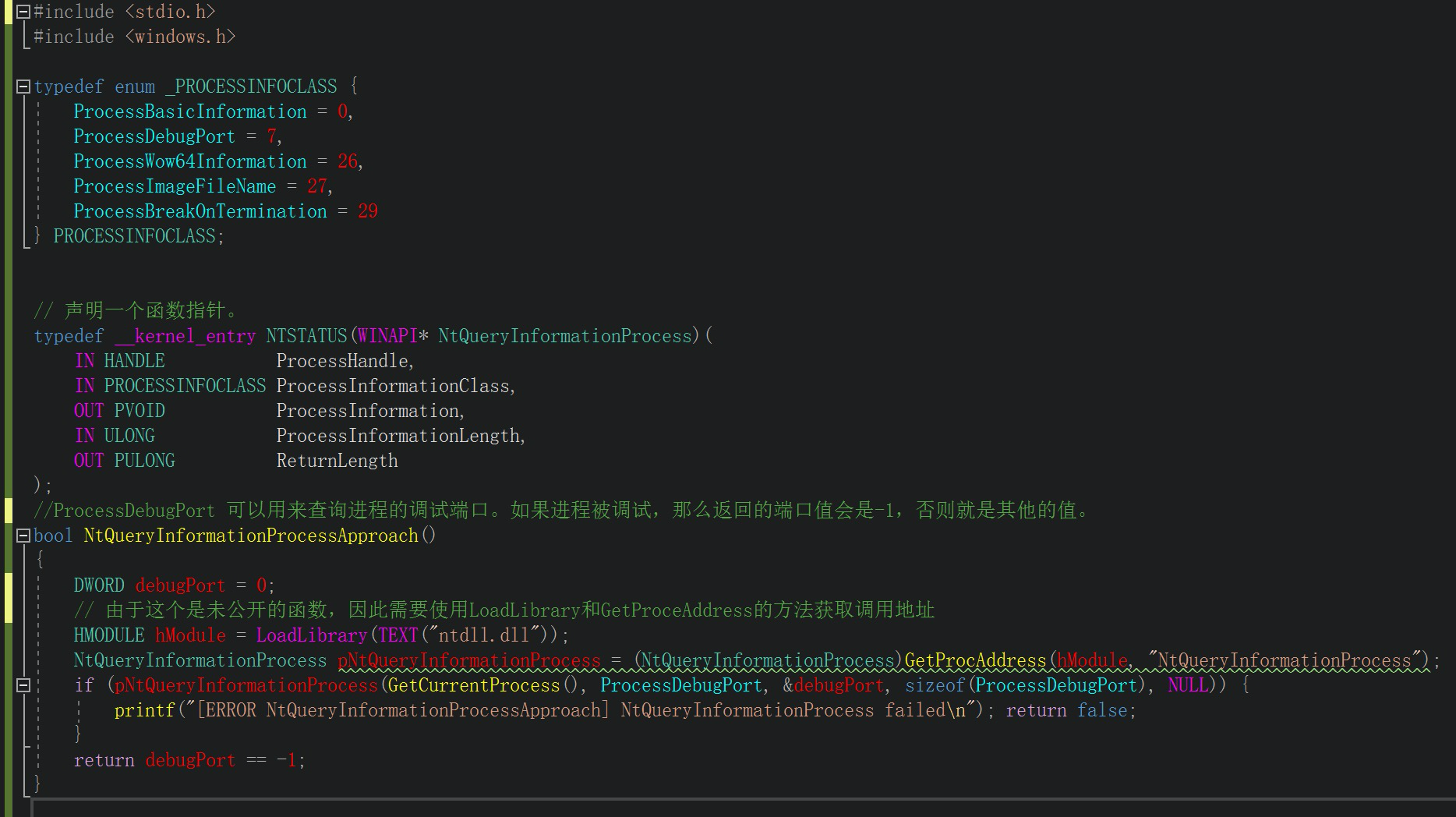
· NtQueryInformationProcess
#include <stdio.h>
#include <windows.h>
typedef enum _PROCESSINFOCLASS {
ProcessBasicInformation = 0,
ProcessDebugPort = 7,
ProcessWow64Information = 26,
ProcessImageFileName = 27,
ProcessBreakOnTermination = 29
} PROCESSINFOCLASS;
// 声明一个函数指针。
typedef __kernel_entry NTSTATUS(WINAPI* NtQueryInformationProcess)(
IN HANDLE ProcessHandle,
IN PROCESSINFOCLASS ProcessInformationClass,
OUT PVOID ProcessInformation,
IN ULONG ProcessInformationLength,
OUT PULONG ReturnLength
);
//ProcessDebugPort 可以用来查询进程的调试端口。如果进程被调试,那么返回的端口值会是-1,否则就是其他的值。
bool NtQueryInformationProcessApproach()
{
DWORD debugPort = 0;
// 由于这个是未公开的函数,因此需要使用LoadLibrary和GetProceAddress的方法获取调用地址
HMODULE hModule = LoadLibrary(TEXT(“ntdll.dll”));
NtQueryInformationProcess pNtQueryInformationProcess = (NtQueryInformationProcess)GetProcAddress(hModule, “NtQueryInformationProcess”);
if (pNtQueryInformationProcess(GetCurrentProcess(), ProcessDebugPort, &debugPort, sizeof(ProcessDebugPort), NULL)) {
printf(“[ERROR NtQueryInformationProcessApproach] NtQueryInformationProcess failed\n”); return false;
}
return debugPort == -1;
}
• 子主题 1
· NtSetInformationThread
// 调试时有断点就会崩溃
void WINAPI StopDebegger()
{
HMODULE hModule = LoadLibrary(TEXT(“ntdll.dll”));
NtSetInformationThreadPtr NtSetInformationThread = (NtSetInformationThreadPtr)GetProcAddress(hModule, “NtSetInformationThread”);
NtSetInformationThread(OpenThread(THREAD_ALL_ACCESS, FALSE, GetCurrentThreadId()), (THREADINFOCLASS)0x11, 0, 0);
}
• 子主题 1

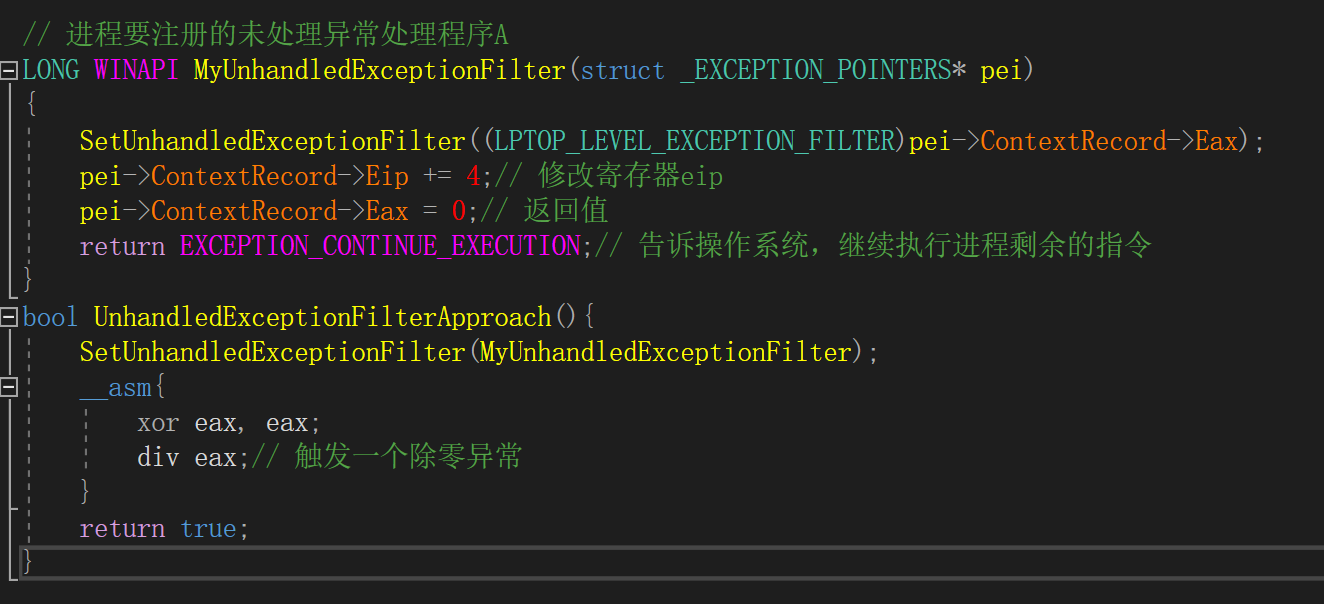
触发异常法
LONG WINAPI MyUnhandledExceptionFilter(struct _EXCEPTION_POINTERS* pei)
{
SetUnhandledExceptionFilter((LPTOP_LEVEL_EXCEPTION_FILTER)pei->ContextRecord->Eax);
pei->ContextRecord->Eip += 4;// 修改寄存器eip
pei->ContextRecord->Eax = 0;// 返回值
return EXCEPTION_CONTINUE_EXECUTION;// 告诉操作系统,继续执行进程剩余的指令
}
bool UnhandledExceptionFilterApproach(){
SetUnhandledExceptionFilter(MyUnhandledExceptionFilter);
__asm{
xor eax, eax;
div eax;// 触发一个除零异常
}
return true;
}
·
断点反调试
· software bpt 0xcc
rep scas ;
时间反调试
…
进程附加抢占
ptrace保护法
调试器端口检测
如23946
父进程检测
/proc/self/status 查看当前进程状态。输出信息中,TracerPid 是个用于判断程序是否被调试的标志,正常运行的程序其值为 0,若处于调试状态,其值为调试器的进程 ID
软件混淆
代码混淆
变量/类名混淆
ollvm控制流平坦化
二进制混淆
无用垃圾指令填充
常量数据进行编码或隐藏
虚拟执行(最难)
资源混淆
软件防篡改
加壳
加密壳
· VMProtect
· Themida
· WinLicense
· ASProtect
· Armadillo
· EXECryptor
· Themida
压缩壳
· UPX
sudo apt-get install upx-ucl
· ASPack
· NSPack
完整性校验
app Signature
资源保护
运行环境检测
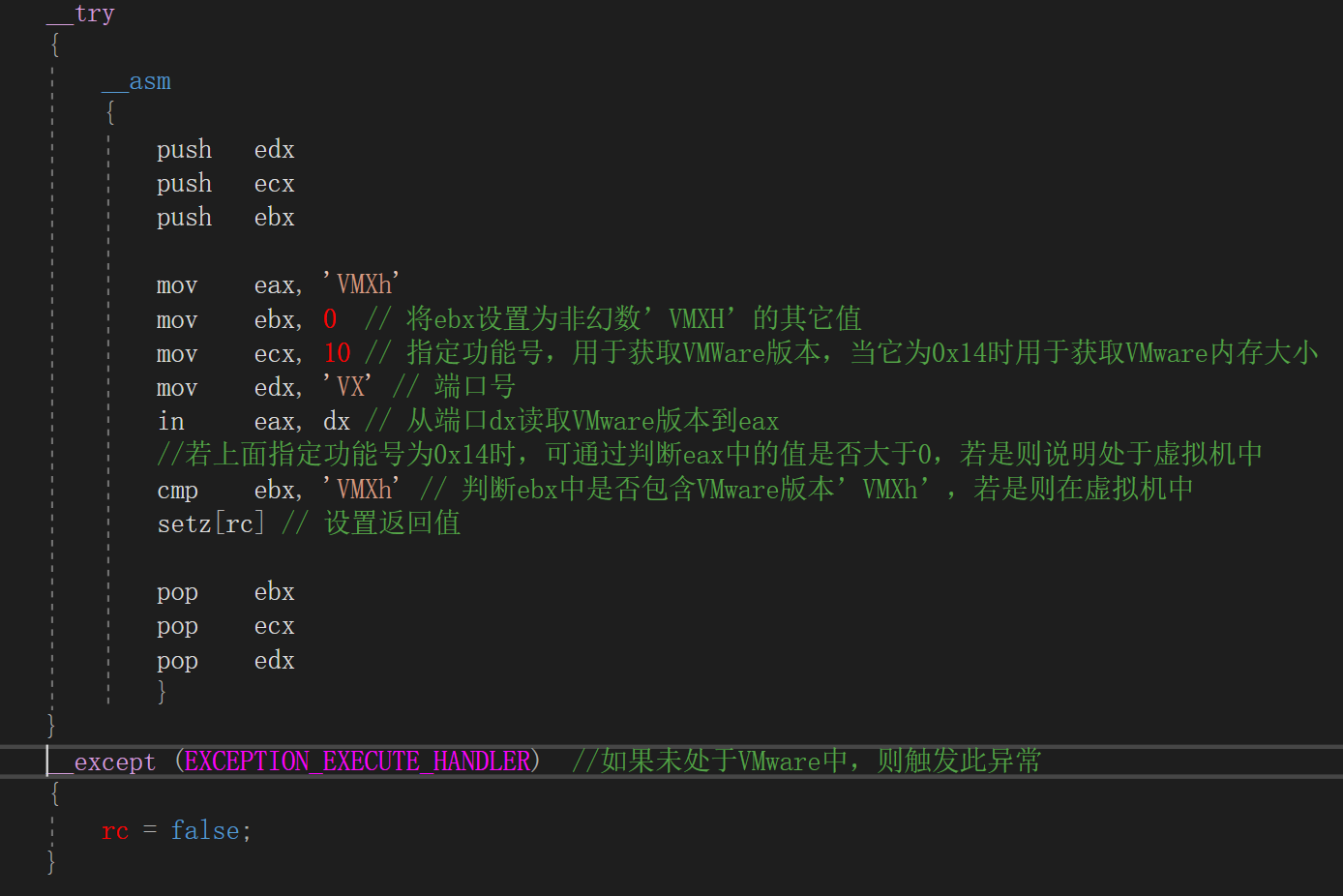
虚拟机检测
vmware
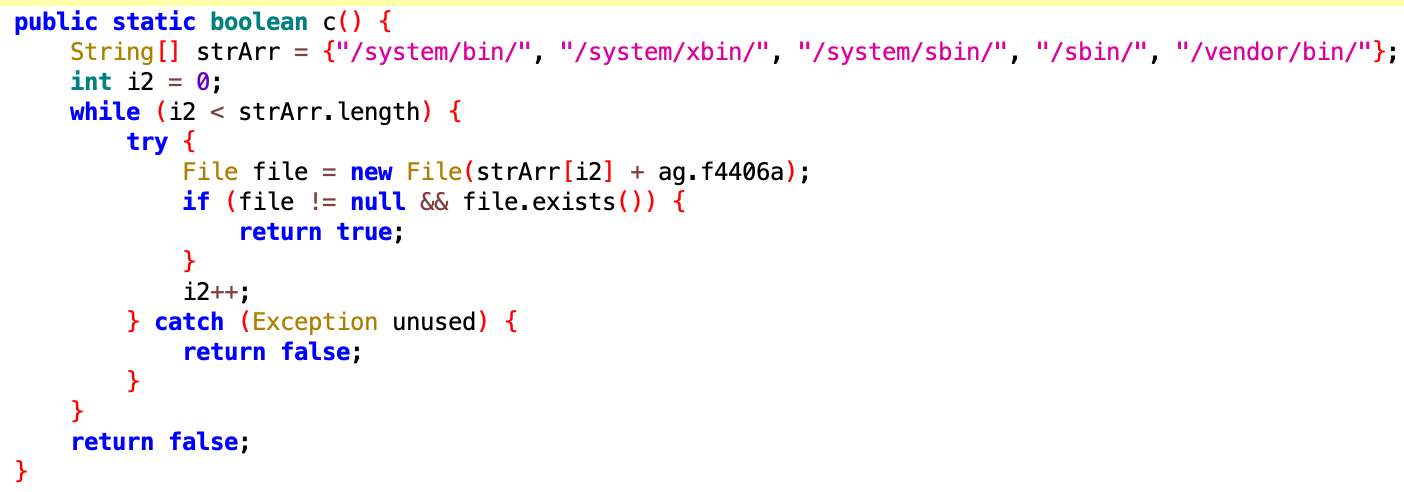
Root检测

hook检测
Hook 框架检测
· de.robv.android.xposed.installer
· de.robv.android.xposed.XposedBridge.main
de.robv.android.xposed.XposedBridge.handleHookedMethod
Java 方法的 Hook 检测
· AndFix
so 动态库的 GOT Hook 检测
so 动态库的 Inline Hook 检测
软件指纹
指发布时在软件特定区域写入特定“指纹”内容,以识别用户身份,防止软件未经授权而被分发